近年來人工智慧技術發展迅速,深度學習等技術的出現和應用已經帶來了很多驚人的成果,尤其是 ChatGPT 的出現更讓人們驚嘆不已。然而這些模型的黑箱特性一直是人工智慧領域中的一個重要議題。為了解決這個問題,越來越多的研究者開始關注解釋性人工智慧技術的發展。XAI 技術在過去幾年中經歷了長足的發展,從最初的可視化技術到現在的基於規則的解釋、深度學習可解釋性技術、模型過程可解釋技術等等,不斷地推陳出新。這些技術的不斷革新和提高,讓人們對於機器學習模型決策過程的理解更加深入和全面,也提高了機器學習模型的可信度和實用性。今天的內容我們將探討 XAI 技術的發展之路,並介紹幾個具有代表性的 XAI 技術。
下圖取自於 Jay Alammar 的部落格,主要說明 XAI 技術中依據模型可解釋性的不同,分成了多種解釋方法。這些方法可分為模型本身具有可解釋性或是過於複雜難以解釋的情況。對於過於複雜的模型,我們需要透過事後分析技術來協助理解模型推論的邏輯。今天提到的所有名詞基本上彼此間都環環相扣,就讓我攘逐一為各位說明。
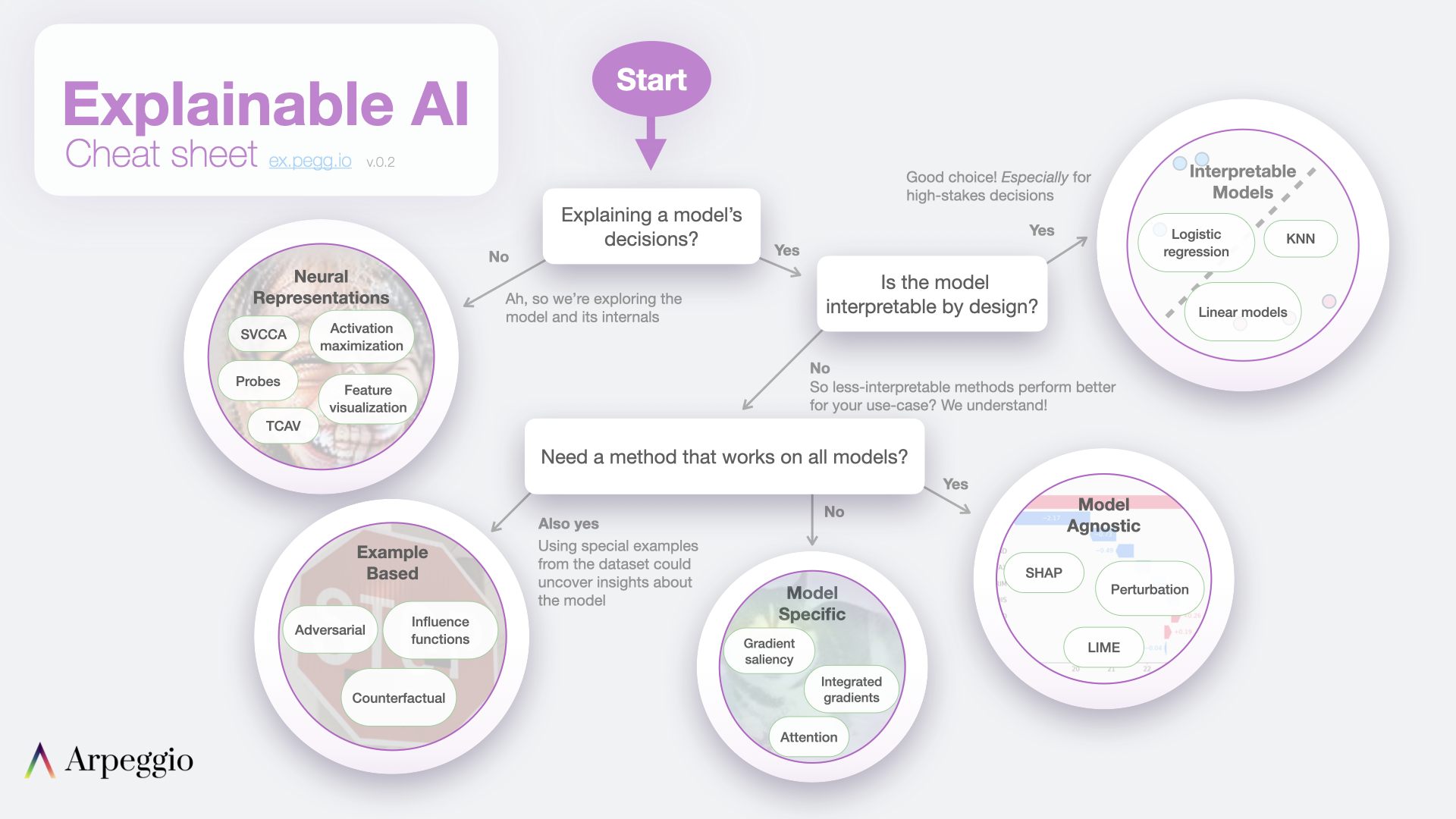
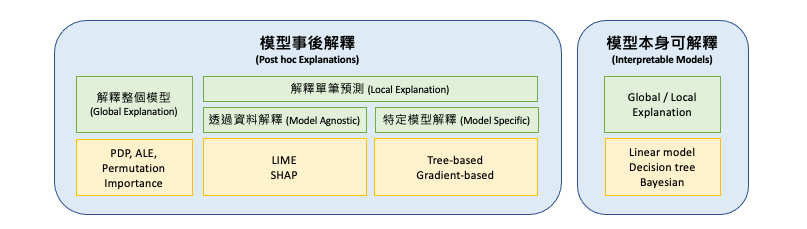
XAI 方法可分為模型本身可以解釋(Interpretable Models)與模型訓練完事後解釋(Post hoc Explanations)兩種。其中,模型本身可以解釋的方法包括:線性迴歸、邏輯迴歸、決策樹、K-nearest neighbors、貝葉斯網絡模型。這些模型在自身設計上就已經具有一定的解釋性,因此可以直接透過模型本身來解釋預測結果。
模型本身可以解釋:
雖然隨機森林和XGBoost通常被認為是比較可解釋的tree-based系列模型,因為其結構相對簡單,可以直觀地理解每個決策的依據。但它們不算是Interpretable Models,因為其決策過程是由多個弱分類器或決策樹共同決定,其整體解釋性較難掌握,需要透過其他解釋方法來進行解釋。
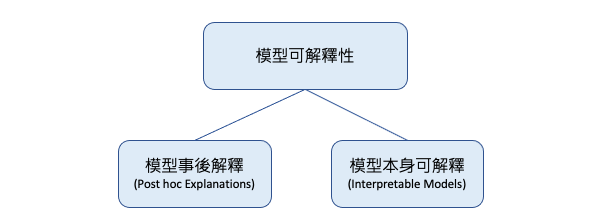
Post hoc Explanations 指的是在模型訓練完畢後,使用額外的解釋方法來理解模型的行為和決策過程。這些方法通常是使用一些數據可視化或統計技術,來顯示模型中不同特徵之間的關係,以及這些特徵對模型結果的影響程度。常見的 Post hoc 解釋方法包括 Permutation Importance、Partial Dependence Plot (PDP)、Accumulated Local Effects (ALE)、SHapley Additive exPlanations (SHAP)、Local Interpretable Model-agnostic Explanations (LIME) 等等。這些方法可以用於解釋各種不同類型的模型,包括決策樹、神經網絡、支持向量機等等。
模型訓練完事後解釋:
剛所提到的模型訓練完事後解釋的方法又可分為 Global 解釋整個模型行為以及 Local 解釋單筆預測行為。Global 的方法的目的是理解模型對所有數據點的預測,而不僅僅是特定的數據點或觀測。這種方法通常涉及到解釋模型中的特徵重要性,即哪些特徵對於模型的預測影響最大。
解釋整個模型的行為,例如:
解釋單筆預測行為,例如:
SHAP 可以同時用於分析全局和局部貢獻,並提供有關每個特徵如何影響模型預測的詳細訊息。
最後 XAI 的方法又可細分為 Model Agnostic 和 Model Specific 兩種。Model Agnostic 的方法是透過資料來解釋模型,例如先前提到的 LIME 和 SHAP 都是透過資料搭配方法來解釋模型的經典方法。
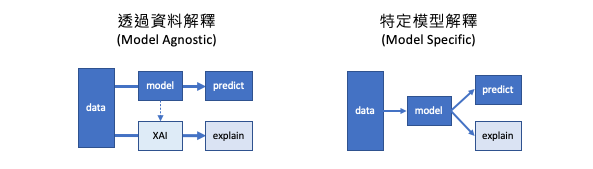
Model Agnostic 不考慮模型本身,只透過資料來解釋模型的方法:
而 Model Specific 的方法則是針對特定模型來進行解釋。例如,決策樹系列的演算法透過樹的分支可知道每個節點的決策,而神經網路透過梯度下降法則可分析每個參數對於輸出的影響。這些方法有助於了解模型的內部運作,但缺點在於限制在特定模型上。
Model Specific 考慮模型本身,解釋模型本身的方法:
以下是一些常用的 Python 可解釋 AI 工具:
除了上述幾個之外還包括 scikit-explain, Skope-rules, DTREEviz, H2O, Yellowbrick, PDPbox, Skater, Ciu, Dalex, Lofo, Anchor, PyCEbox, Alibi, Captum, AIX360, OmniXAI, L2X。這些都可以透過 Python 來輔助我們解釋訓練好的模型。
本系列將會挑選幾個具有代表性的工具介紹給各位邦友
最後用這張圖表做個總結,並統整了今天所學習的內容。簡單來說,要解釋機器學習模型的結果,可以採用模型事後解釋或模型本身可解釋的方式。透過模型事後解釋,我們可以進一步了解模型在特定數據上的表現,以及模型背後的推論過程。而模型本身可解釋的模型則可以提供直接的解釋,因此可以更好地理解模型在不同情況下的預測結果。此外,解釋整個模型可以揭示模型的整體結構和特徵重要性,而解釋單筆預測可以幫助我們理解模型如何進行個別預測。透過資料解釋可以解釋各種不同類型的模型,而特定模型解釋則專注於針對特定類型的模型進行解釋。
明天我們就來談談這些關於機器學習中的可解釋性的指標

